Using GitHub as a Mentoring Tool
Looking Experts over their Shoulders
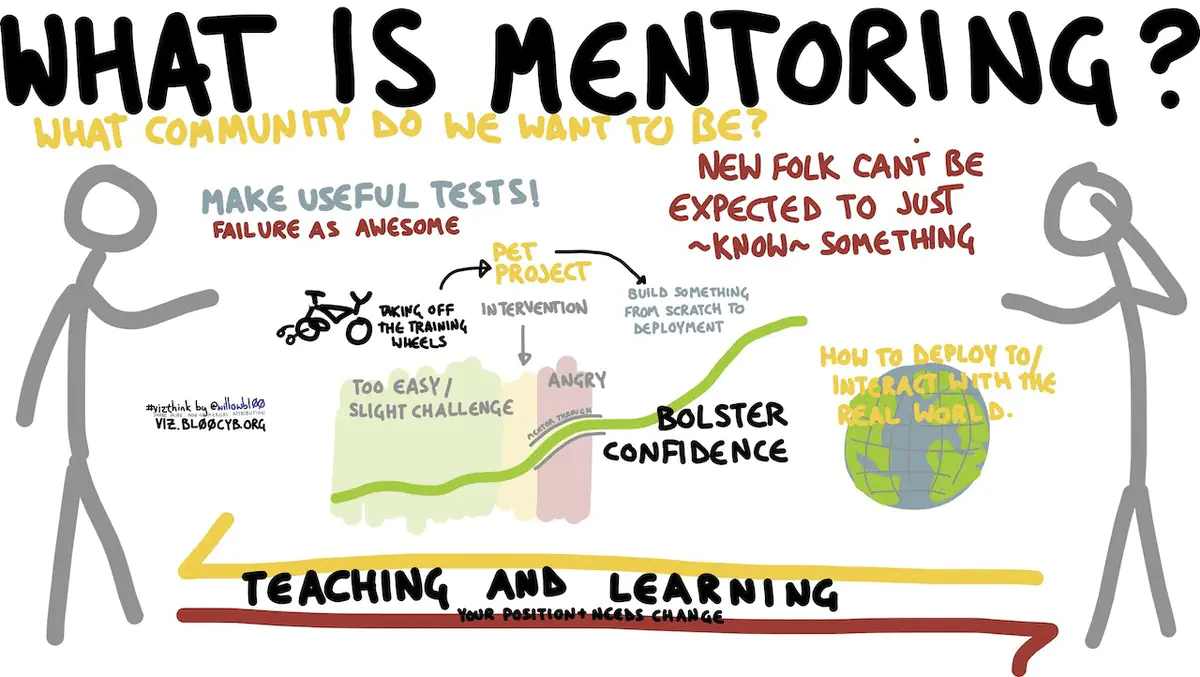 What is mentoring? by Willow Brugh, CC BY-SA 2.0, via Wikimedia Commons
What is mentoring? by Willow Brugh, CC BY-SA 2.0, via Wikimedia CommonsBeginner, Intermediate, and Expert Level
For several years I am interested to learn R, the free software environment for statistical computing and graphics. After
- reading several books,
- finished some (paid) introductory (MOOC) courses successfully with Coursera
- and especially some smaller (paid) projects
I would say that I am now (stuck?) on an intermediate skill level. I believe that this is the most challenging step in progressing to an expert for a self-determined learner. There are always so many different avenues to follow up. This is especially true with R and its
- ever increasing amount of new R packages (To date: 20010 (MRAN) resp. 17954 (CRAN), 3452 (Bioconductor).
- hundreds of books (see: the searchable list on r-project.org, a curated list on GitHub by Roman Tselgelskyi, but also my Wakelet on free R Books
- an unknown number of (free) online tutorials (see the general list and university listed free R tutorials by Pairach Piboonrungroj and my Wakelet on learn R programming)
Comparing my skill level with the three learner paths suggested by RStudio Education, I could affirm my personal assessment. From the six tasks proposals on the intermediate path
- grab some R cheat sheets
- learn to get help (see, for instance, my activities on StackOverflow)
- improve your visualizations
- develop interactive applications with htmlwidgets and Shiny
- simplify your model explorations with tidymodels
- explore other specialized packages
I have some skills with the first three, and I also experimented already with Shiny. I even had worked on some steps at the expert levels by writing an R package: (bib2academic got 16 stars, but I did not manage to submit it to CRAN. It is now obsolete as a similar function was integrated into the Academic Hugo website (now Wowchemy website builder).
Project for Motivation Necessary
But to continue this path, I would need some strong motivation. I tried, for instance, to read the (not yet finished) book Mastering Shiny. As with all books and papers by Hadley Wickham, it is well written and exciting. But to learn continuously, I would need a practical project where I get not only real-world challenges but also a strong personal motivation to complete the product. In finishing the project/product, I would have to learn to overcome several real-world challenges where I would need to look for help and consult/experiment with several new functions or packages.
But this strategy has two advantages:
- It is very laborious as the specific questions are not (yet) clear enough. Fora like StackOverflow are not suitable as the problem space is not delimited, a concrete coding question with a REPREX (REPRoducible EXamples) is not available.
- It is error-prone and not efficient. Am I posing the right question? Do I look at the right places? It is not guaranteed that one finds the optimal solution. This is particularly awkward if the answer in the R community is very well known.
Looking for a Human Mentor
I believe with a mentor, one could overcome these insecurities fast. The mentor — an experienced user — could ask questions to narrow the search space and point out helpful hints about what and where to look. Wikipedia, for instance, has established a similar program for their user community called Adopt-a-user.
The Adopt-a-user program is designed to help new and inexperienced users by pairing them with more experienced Wikipedians. These editors (referred to as adopters or mentors) will “adopt” newer users, guiding them along the way as they learn about Wikipedia and its various aspects. (Wikipedia)
In Wikipedia, the intention is to help novice contributors get orientation and some guided practice with the very complex rule set for writing or changing Wikipedia entries. My thought is to find a mentor to advance at the intermediate level. I think there is plenty of material for the R beginners freely available. But more important: You will learn R from scratch as an individual and do not need to worry at the beginning stage about an already developed complex rule which you have to observe and follow.
As far as I know, there is no mentor program for R users. The next best alternative is a more open and friendly community. An excellent example, in my opinion, would be the RStudio Community. But even there, you should have a concrete question to ask.
GitHub as a Mentoring Tool
An instructive example
I recently found out that GitHub could be used as an educational tool. I will you give an example which was very exciting for me:
Often I was confronted with the problem of how to calculate and format nicely a contingency table in R. The free web material on the web on this question is abound (e.g., Datacamp, Data Science Central, R-Bloggers, TechVidvan, Statology, …). But many examples still teach the Base R commands. They do not mention new procedures with the tidydata approach and related packages like tidyr. And they do not worry about outputting the table in a publishing-ready format.
There are many contingency tables published in the recently finished books Introduction to Modern Statistics.
| Group | Stroke | No event | Stroke | No event |
|---|---|---|---|---|
| Control | 13 | 214 | 28 | 199 |
| Treatment | 33 | 191 | 45 | 179 |
| Total | 46 | 405 | 73 | 378 |
I could look up the source code from lines 85-101 via GitHub and learn how to produce the above table. (In the following code chunk, I have focussed on the table appearance and left out different previous data transformations to prepare the two data sets stent30 and stent365. Furthermore, the code differs somewhat from the original due to some CSS styles of this website.).
```{r stent-study}
suppressMessages(library(janitor))
suppressMessages(library(kableExtra))
suppressMessages(library(openintro))
suppressMessages(library(tidyverse))
stent %>%
mutate(group = str_to_title(group)) %>%
pivot_longer(cols = c(`30 days`, `365 days`),
names_to = "stage",
values_to = "outcome") %>%
count(group, stage, outcome) %>%
pivot_wider(names_from = c(stage, outcome), values_from = n) %>%
adorn_totals(where = "row") %>%
kbl(linesep = "", booktabs = TRUE, caption = "Descriptive statistics for the stent study.",
col.names = c("Group", "Stroke", "No event", "Stroke", "No event"),
table.attr = "style='width: 75%;'") %>%
add_header_above(c(" " = 1, "30 days" = 2, "365 days" = 2), extra_css = "border-bottom: 2px solid") %>%
row_spec(1, extra_css = "border-top: 2px solid") %>%
row_spec(3, extra_css = "border-top: 2px solid") %>%
kable_styling(bootstrap_options = c("striped", "condensed"),
latex_options = c("striped", "hold_position"),
full_width = T, position = 'center')
```
Lesson learned
Looking into the source code at GitHub, I learned several issues:
- I experimented already with the
janitorpackage, and I am happy to get the confirmation that it is a widely used package to “provide quick counts of variable combinations (i.e., frequency tables and crosstabs)” and to “format [nicely] the tabulation results.” (From the Janitor package description.) - I also did know about the
kableExtrapackage and had thekable_stylingfunction already used several times. - The other
kableExtrafunctions (add_header_above(),row_spec(),kbl()) I had not used before. Especiallyadd_header_above()has an important role for special headings in contingency tables. - The parameter
extra_csswas entirely new for me. I have never heard about it and didn’t even know that it exists.
For me, this learning experience was very instructive! I admit that this example could have been asked via a friendly forum: For instance: “How could I produce a contingency table formatted professionally for print by using the tidyverse approach?” Additionally, one would have to provide some code to show where one stands and what approach one is using.
Looking Experts over their Shoulders
But this was just one example where I knew about the problem and had already tried several approaches to find a solution. But what about code patterns I didn’t even know and could therefore not ask the right question?
Finding a GitHub project with code snippets one needs urgently is just the beginning. There is a big chance that the same repository (aka ‘repo’) hides more code snippets to learn from. And maybe the person behind this one GitHub repos maintains other repositories that are also very interesting?
In my case, it turned out that Mine Çetakaya-Rundel, one of the authors and the person responsible for the repository management, has educational approaches that are similar to mine. But she is way off more skilled in R and statistics. I am especially interested in her usage of the learnr package for interactive tutorials and have watched a series of three videos on Teaching Statistics and Data Science Online.
In a certain sense, she functions as a mentor for me — even if she doesn’t know about it 🥸. Meanwhile, we had some exchanges on GitHub issues as I am interested in learning how to use the learnr package for introductions into statistics via R-Tutorials. Regularly if I find a problem as a user reading and following the tutorial exercises, I try to fix the code in my fork and send the solutions as pull requests (PR) to Mine. Besides learning to use GitHub in a collaborative setting, I have already profited in many ways. I learned about packages I have never heard of (see, for example, the list of packages used for the book) and saw code snippets that transformed data in a much more elegant way as I used to do.
Summary
To inspect code on GitHub is a suitable strategy for intermediate (programming) learners. I illustrated it with an R example, but I think you could generalize it as a learning strategy. I recommend the following steps:
- Note names and/or repositories you learned from successful internet recherche. By searching answers or asking questions via StackOverflow, you will encounter the same names, blog addresses, Twitter messages, repos again and again.
- Look around if these person/websites generally work on problems you are interested in. Look into the profile and follow the activities of these persons on their blog, Twitter, YouTube, GitHub … accounts.
- Decide on a person and select a specific project. I recommend focusing not only on a particular person but also on picking one project to concentrate on. Ideally, it is a current project the person is still interested in and produces code you want to learn and use for your own work later on.
- Think about a possibility to get involved in the project. The idea is to give the person and the community something back for its/their mentoring function and commit yourself to relevant real-world problems. The possibilities depend on your skills and interests. It may be advertising the project, writing a favorable review, fixing typos, commenting via the issue part of the repo, recommending code changes via PRs, or financially supporting the author(s) and/or the ongoing project.
Finally, I would like to add also a warning: “Following” a person should not develop to stalking. It is essential not to be intrusive or pushy. You will see already after a short time if the person values your contribution(s), e.g., by answering friendly or thoughtfully, accepting your PRs, etc. If you get the impression that your engagement is disruptive, then stop it immediately. Either look at the code silently without interaction or try to find another “mentor” or project to get involved.
Peter Baumgartner
Retired Professor of Technology Enhanced Learning (TEL)
My research interests include eLearning, educational technology, educational design, open science and data science education.